

Traffic delays at signalized intersections are a key factor in evaluating the performance of transportation networks, significantly affecting urban mobility systems. According to Alatoom and Al-Hamdan, traffic delay is the extra time vehicles spend at intersections compared to the time required in ideal conditions. Accurately estimating this delay is vital for effective traffic planning, intersection design, and optimizing signal timing. Inefficient traffic management at intersections can lead to prolonged delays, which contributes to congestion, increases fuel consumption, raises emissions, and degrades the quality of service for users of the road.
Many previous studies recognize three distinct categories of delay that occur at signalized intersections: control delay, stopped delay, and approach delay. Control delay encompasses the total vehicular delay experienced at the intersection. Stopped delay specifically measures the duration during which vehicles remain stationary until the subsequent green phase initiates. Approach delay incorporates both the stopped delay and additional time losses resulting from vehicle deceleration when approaching the intersection and re-acceleration when departing. Each type of delay provides different insights into intersection performance and requires specific modeling approaches to estimate accurately.
Traditionally, transportation engineers rely on two primary methodologies to evaluate traffic delays at signalized intersections. The first approach involves conducting field studies, which, while providing direct observational data, proves to be resource-intensive and logistically challenging, particularly in developing regions with limited resources. The second approach employs predictive models, which have gained widespread adoption among transportation agencies as a more practical alternative to field studies. However, these conventional models often suffer from significant inaccuracies in their predictions, leading to potentially flawed traffic planning and management decisions.
The reliability of delay estimation directly impacts the effectiveness of traffic management strategies and infrastructure investments. When predictions are inaccurate, transportation agencies may implement suboptimal signal timing plans, incorrectly assess level of service, or misallocate resources for intersection improvements. This highlights the critical need for more accurate and robust delay estimation techniques that can capture the complex dynamics of modern traffic conditions, particularly in the context of increasing urbanization and evolving transportation patterns.
The development of traffic delay estimation models has undergone significant evolution over several decades, reflecting advances in mathematical modelling, computational capabilities, and data collection methodologies. The earliest notable contribution to this field was made by Webster, who developed a mathematical model for homogeneous traffic based on the concept of degree of saturation at signalized intersections. This pioneering work established the foundation for subsequent analytical approaches to delay estimation.
Following Webster’s work, the Federal Highway Administration introduced the Highway Capacity Manual (HCM) model, which has become one of the most widely utilized frameworks for estimating signalized delay based on multiple traffic parameters. The HCM model incorporates various factors including traffic volume, saturation flow rates, signal timing, and intersection geometry to produce delay estimates that inform level of service determinations. Akcelik further expanded the methodology by developing a generalized model based on the HCM approach, with the objective of creating an internationally applicable framework for traffic delay estimation at signalized intersections.
These models were primarily founded on homogeneous traffic conditions and theoretical assumptions that often fell short in capturing the complexities of real-world intersections. This limitation became particularly evident in heterogeneous traffic environments, where the interaction between different vehicle types and driver behaviours introduces additional complexity that purely analytical models struggle to represent accurately.
The statistical approach emerged as a method, with researchers developing delay estimation models based on traffic, geometric, and signal timing parameters using techniques like probabilistic methods for estimating delay from traffic volume and saturation flow, as well as analytical models for congestion influenced by green ratios and geometry. Yet, statistical models still relied on simplified assumptions that failed to capture the dynamic nature of signalized intersections, especially under varied traffic conditions common in urban areas. The complexity of traffic patterns and numerous variables influencing intersection performance posed significant challenges for traditional modelling methods.
With rapid advancement in technology, the integration of artificial intelligence into various domains of civil engineering, including transportation, has been very popular among researchers. Several researchers have explored the application of machine learning techniques for addressing complex traffic engineering challenges. The inherent ability of these algorithms to identify patterns in large datasets and model non-linear relationships makes them particularly well-suited for traffic delay estimation, where multiple factors interact in complex ways.
Alatoom and Al-Hamdan’s research from Iowa State University in Ames, Iowa, USA, features a thorough evaluation framework that goes beyond simply measuring prediction accuracy. This comprehensive approach recognizes that for transportation agencies to effectively implement delay estimation models, they must consider various performance aspects in addition to predictive ability.
The dataset utilized in this study includes traffic delay observations from eight isolated intersections in Amman, Jordan. Key parameters recorded in the dataset comprise Arrival Rate (V), which reflects the number of vehicles per hour; the Effective Green Time to Cycle Length Ratio (g/C); Degree of Saturation (Xs); Lane Width (W); and Stopped Delay (Ds), which serves as the target variable. Data collection was carried out using video monitoring and field measurements to ensure accuracy. Following this, the dataset was divided into two subsets for analysis, with 80% designated for training and the remaining 20% for testing purposes. The study uses ORANGE software package (as shown in figure below) to preprocess, train, and evaluate the machine learning models.
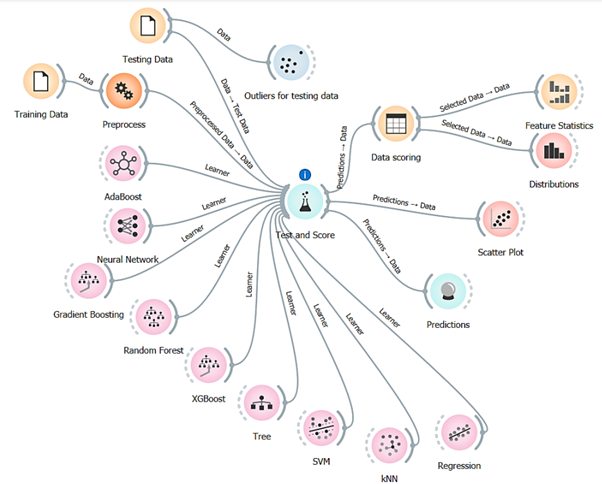
The study conducted a rigorous comparison of nine distinct machine learning algorithms: Artificial Neural Networks (ANN), Random Forest (RF), Decision Tree, Support Vector Machine (SVM), K-Nearest Neighbor (K-NN), AdaBoost, Gradient Boost, XGBoost, and Partial Least Squares (PLS) regression. Each algorithm represents a different approach to model building and prediction, with unique strengths and limitations that influence their suitability for delay estimation applications.
In order to evaluate the accuracy of predictions, researchers utilized a range of metrics including the Root Mean Square Error (RMSE), Mean Absolute Error (MAE), and the coefficient of determination (R²). This comprehensive methodology offers a more thorough assessment than reliance on a singular performance metric. The researchers furthermore investigated the disparity between training and testing performance, which highlights a model’s ability to generalize to novel datasets.
Grasping this distinction is crucial for models aimed at accommodating diverse traffic conditions. The evaluation of computational time took into account the practical constraints encountered by transportation agencies. Through the examination of model training and prediction durations, valuable insights were obtained concerning operational feasibility, particularly in the context of real-time traffic management scenarios. Finally, the robustness of the model was assessed by analyzing performance consistency across various subsets of data, thereby reflecting reliability in differing traffic situations and ensuring stable performance in a range of contexts.
In machine learning, different models demonstrate varied performance levels in predictive tasks, as illustrated in the table below.
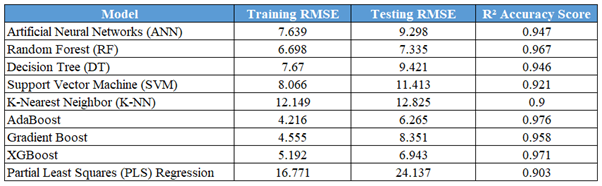
Among the nine machine learning algorithms evaluated, the Random Forest model exhibited the most balanced and robust performance, achieving an average error below 4% and a score of 35 out of 45 in the evaluation framework. Its ensemble nature reduces the risk of overfitting by averaging predictions from multiple decision trees trained on different data subsets, leading to stable and reliable outcomes. The algorithm efficiently handles non-linear relationships inherent in traffic delay estimation, simplifying implementation without sacrificing accuracy.
Additionally, Random Forest offers built-in feature importance metrics, allowing transportation engineers to identify key factors impacting delays, enhancing trust in the model’s predictions. Its computational efficiency makes it suitable for offline planning and real-time traffic management, while its stability across various data subsets ensures consistent performance across diverse urban environments.
Alatoom and Al-Hamdan’s comparative analysis highlighted significant limitations in conventional analytical models for estimating vehicular delays at signalized intersections. Models such as the Highway Capacity Manual (HCM), Webster, and Akçelik showed error rates 5 to 58 times higher than machine learning methods. These discrepancies stem from traditional models being based on theoretical assumptions that often don’t reflect real-world conditions, particularly in diverse urban environments.
Moreover, analytical models such as, Fundamental Diagram Models, Queuing Theory Models, Dynamic Traffic Assignment (DTA) Models, Macroscopic Traffic Flow Models, Microscopic Traffic Flow Models, Transitional Flow Models, Empirical Models, and Travel Demand Model use deterministic frameworks that fail to capture the stochastic nature of traffic, influenced by various factors like time and weather. Their reliance on simplified, often linear relationships between traffic parameters and delays further limits their accuracy.
In contrast, machine learning algorithms like Random Forest and neural networks effectively model the complex, non-linear interactions involved. The findings stress that traditional models require careful calibration to local conditions; otherwise, uncalibrated applications could lead to significant errors, affecting signal timing, service assessments, and resource allocation. Therefore, either calibration or a shift towards machine learning methodologies is essential for better accuracy in delay estimation.
In context to practical implications, transportation agencies can significantly enhance level of service (LOS) assessments at signalized intersections through machine learning models. With delay being the primary criterion for LOS, more accurate delay estimates can improve evaluations of intersection performance and help identify problematic areas needing intervention. This accuracy leads to better resource allocation for improvements.
Machine learning can also enhance signal timing optimization by providing improved delay estimations, allowing for the creation of more effective timing plans that reduce overall delay. Models like Random Forest not only optimize traffic signal timing but also offer insights into the importance of various timing parameters.
For traffic engineers, integrating machine learning into intelligent transportation systems (ITS) provides advantages in computational efficiency and accuracy for real-time decision-making based on traffic conditions. However, successful implementation relies on high-quality data, making the development of comprehensive data collection systems at intersections crucial for training these models effectively.
In conclusion, the findings highlight the superior performance of machine learning approaches, particularly the Random Forest algorithm, which achieved an average error below 4%. This marks a substantial improvement over conventional models, which had error rates 5 to 58 times higher. The research introduces a comprehensive evaluation framework that considers not only prediction accuracy but also training-testing performance, sensitivity to outliers, computational cost, and model robustness. This multifaceted approach enhances the understanding of each algorithm’s suitability for various traffic environments.
The study warns against using uncalibrated traditional models, as their significant error margins can lead to flawed traffic planning and resource allocation. Looking ahead, integrating machine learning into traffic engineering practices offers a promising avenue for improving urban mobility management, especially as systems become more complex and data-driven. The Random Forest algorithm stands out as a reliable solution for enhancing delay estimation accuracy.
Reference
Alatoom, Y. I., & Al-Hamdan, A. B. (2024). A Comparative Study Between Different Machine Learning Algorithms for Estimating the Vehicular Delay at Signalized Intersections. Journal of Soft Computing in Civil Engineering, 9(1), 123-158. DOI: 10.22115/scce.2024.418800.1725
Webster VF. Traffic Signal Settings. Road Research Technical Paper No. 39. Berkshire, England: Road Research Laboratory, Her Majesty’s Stationery Office; 1958.
HCM. Highway Capacity Manual. Washington, D.C.: Transportation Research Board; 1992.
Akcelik R. The Highway Capacity Manual Delay Formula for Signalized Intersections. ITE J 1988;58:23–7.
Ashrafian A, Safaeian Hamzehkolaei N, Dwijendra NKA, Yazdani M. An Evolutionary NeuroFuzzy-Based Approach to Estimate the Compressive Strength of Eco-Friendly Concrete Containing Recycled Construction Wastes. Buildings 2022;12:1280. https://doi.org/10.3390/buildings12081280.