

Landslide susceptibility prediction represents a critical component in disaster risk reduction frameworks, enabling authorities to identify areas with higher probabilities of landslide occurrence. The evolution of Landslide Susceptibility Prediction (LSP) methodologies has witnessed significant advancements over recent decades, particularly with the integration of Geographic Information Systems (GIS) and remote sensing technologies. These technological tools have facilitated the development of increasingly sophisticated prediction models capable of processing complex spatial data. According to the researchers, LSP approaches can be broadly categorized into qualitative and quantitative models, with the latter further divided into data-driven and deterministic approaches. Deterministic models calculate quantitative stability coefficients but require detailed soil mechanical parameters and are consequently limited in their application to large regions with heterogeneous conditions. Data-driven models, conversely, operate by identifying relationships between historical landslide locations and various environmental conditioning factors, making them more suitable for large-scale LSP applications.
Within the data-driven approach, three primary categories have emerged as dominant methodologies for landslide susceptibility prediction: heuristic, general statistical, and machine learning models. Heuristic models employ expert knowledge through ranking and rating methodologies, with the Analytic Hierarchy Process (AHP) representing a widely used technique that organizes conditioning factors in a hierarchical structure and determines their relative importance through pairwise comparisons. General statistical models establish linear correlations between recorded landslides and conditioning factors, represented by the General Linear Model (GLM) and Information Value (IV) approaches that quantify relationships through statistical measures. Machine learning models represent the most advanced category, encompassing techniques such as Binary Logistic Regression (BLR), Multilayer Perceptron (MLP), Back-Propagation Neural Network (BPNN), Support Vector Machine (SVM), and decision trees like C5.0 DT1. These sophisticated algorithms can address non-linear correlations between landslides and conditioning factors while automatically optimizing model parameters through iterative learning processes.
Comparing landslide susceptibility (LSP) prediction models is crucial for disaster risk management. Researchers lack consensus on the best models, highlighting the need for studies evaluating performance across methods. Even slight improvements in prediction accuracy can significantly influence landslide susceptibility maps and their regional patterns. The research in Shicheng County is one of the few comprehensive studies comparing heuristic, statistical, and machine learning models in a single area. This approach not only identifies the best-performing models but also reveals reasons for performance differences, enhancing the theory of LSP modelling.
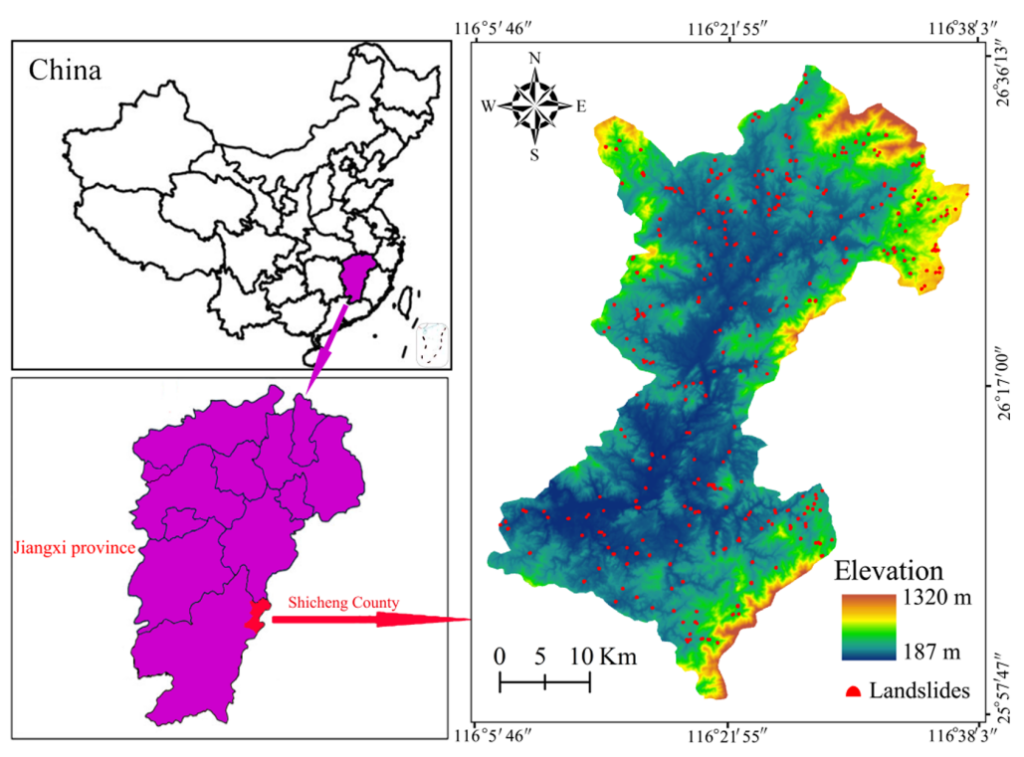
Shicheng County in China was selected as the study area for this comprehensive landslide susceptibility analysis due to its significant vulnerability to landslide events. The region experiences frequent landslide occurrences that pose serious threats to local communities, infrastructure, and ecological environments. The study utilized a substantial dataset comprising 369 landslides identified through rigorous field investigations, providing a robust foundation for model training and validation. These landslides were systematically divided into training (70%) and testing (30%) datasets to ensure reliable model development and independent performance assessment. The geographic context of Shicheng County presents a diverse landscape with varied topography, geology, and land use patterns, making it an ideal testing ground for comparing different landslide susceptibility prediction approaches. The environmental complexity of this region allows researchers to evaluate the effectiveness of various modelling techniques under challenging real-world conditions that typify many landslide-prone areas globally.
The study incorporated thirteen distinct landslide conditioning factors to characterize the environmental conditions influencing landslide susceptibility throughout Shicheng County. These factors encompassed topographic variables namely, elevation, slope, aspect, plan curvature, profile curvature, relief amplitude, distance to river, topographic wetness index (TWI), Normalized Difference Vegetation Index (NDVI), total surface radiation, population density and rock types. This comprehensive set of conditioning factors represents the multiple dimensions of landslide causation, capturing both natural and anthropogenic influences on slope stability. The researchers acquired these datasets from diverse sources including free remote sensing images, Digital Elevation Model (DEM) analysis, field investigations, and government reports, ensuring a multi-perspective approach to landslide susceptibility assessment. To determine the relevance of each conditioning factor in relation to landslide occurrence, the study employed frequency ratio analysis, which quantitatively assessed the spatial correlation between factor classes and landslide locations.
The implementation of the eight landslide susceptibility models followed a structured methodological framework designed to ensure scientific rigor and comparative validity. Initially, the frequency ratio analysis was applied to determine the appropriate conditioning factors and calculate their effects on landslide occurrence, providing a quantitative measure of factor importance. This preparatory analysis informed the subsequent stage where input-output variables and training-testing datasets were carefully constructed to maintain consistency across all modelling approaches. The researchers then proceeded to build and calibrate each of the eight models (AHP, GLM, IV, BLR, MLP, BPNN, SVM, and C5.0 DT) based on the established spatial datasets, implementing the specific algorithmic requirements of each modelling approach. Following model development, landslide susceptibility indexes (LSIs) were calculated for the entire study area, enabling the production of comprehensive landslide susceptibility maps for Shicheng County. The final stage involved rigorous validation of model performance using the area under receiver operating characteristic curve (AUC) metric, which provides an objective measure of prediction accuracy by assessing the model’s ability to correctly classify landslide and non-landslide locations1. This systematic evaluation methodology allowed for direct comparisons between the different modeling approaches while maintaining scientific objectivity.
The evaluation of eight landslide susceptibility models utilized rigorous validation techniques based on the Area Under the Receiver Operating Characteristic Curve (AUC). Researchers employed an independent testing dataset, consisting of 30% of landslides not used in training, for an unbiased model performance assessment. Additionally, the evaluation considered the spatial distribution of landslide susceptibility indexes (LSIs) in Shicheng County, checking if predicted patterns matched known geological features of slope instability. This dual assessment, combining statistical accuracy with spatial analysis, effectively compared the strengths and limitations of different models.
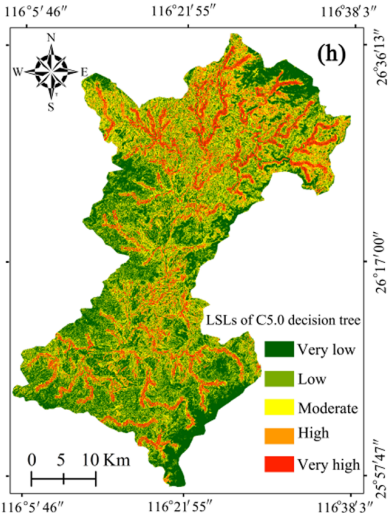
The analysis showed machine learning models consistently outperformed statistical and heuristic methods. The C5.0 Decision Tree achieved the highest prediction accuracy with an AUC of 0.868, followed by SVM (0.813), BPNN (0.803), and MLP (0.792). The Binary Logistic Regression model outperformed traditional statistical models with an AUC of 0.784. General statistical models showed moderate capabilities, with the General Linear Model and Information Value model scoring 0.779 and 0.774, respectively. The Analytic Hierarchy Process had the lowest AUC at 0.773, yet retained reasonable predictive capability. All models produced accurate landslide susceptibility predictions, with performance differentials offering insights into their strengths. Notably, while differences between models were often small, the transition from heuristic to machine learning methods marked a significant accuracy improvement that could influence disaster risk management decisions.
The findings from this comprehensive comparative study hold significant implications for practical landslide risk management across diverse geographic contexts. The superior performance of machine learning approaches, particularly the C5.0 Decision Tree model, suggests that disaster management agencies could substantially improve their landslide susceptibility assessments by implementing these advanced techniques. More accurate landslide susceptibility maps enable authorities to prioritize high-risk areas for mitigation measures, including engineering interventions, monitoring systems, and early warning networks. The quantitative performance differences between modelling approaches translate into practical differences in the spatial distribution of landslide susceptibility levels, potentially affecting land-use planning decisions, infrastructure development regulations, and emergency response preparations. For regions with similar geological and geomorphological characteristics to Shicheng County, the study provides specific guidance regarding which modelling approaches are most likely to yield reliable susceptibility predictions. Beyond the technical aspects, the research emphasizes that even incremental improvements in prediction accuracy can have substantial real-world impacts by reducing the uncertainty in hazard assessments and potentially preventing the loss of life and property through more targeted preventive measures.
In conclusion, machine learning models, particularly the C5.0 Decision Tree, demonstrated superior predictive capability compared to general statistical and heuristic approaches when applied to the landslide-prone terrain of Shicheng County in China. This performance hierarchy reflected the fundamental strengths and limitations of each modelling approach, with machine learning techniques excelling through their ability to capture complex non-linear relationships between environmental factors and landslide occurrence. The research confirms that while all eight models produced reasonably accurate predictions, the choice of modelling approach can significantly impact the reliability of landslide susceptibility mapping and consequently influence disaster risk management decisions.
The practical implications of this study extend beyond academic comparisons, offering valuable guidance for governmental agencies, environmental management organizations, and disaster preparedness authorities. The quantitative performance differences between modelling approaches translate into real-world differences in hazard assessment accuracy, potentially affecting everything from infrastructure planning to emergency response protocols. As climate change and human activities continue to modify landscapes and potentially increase landslide risks in many regions, the implementation of optimal prediction methodologies becomes increasingly crucial for effective disaster risk reduction.
Future advancements in landslide susceptibility prediction will likely emerge from hybrid approaches that combine the strengths of different modelling categories, dynamic models that incorporate temporal variables alongside static conditioning factors, and ensemble techniques that leverage multiple prediction algorithms to reduce uncertainty. These methodological innovations, building upon the comparative insights generated by this study, could further enhance the accuracy and reliability of landslide susceptibility assessments. Ultimately, the continued refinement of prediction methodologies represents an essential contribution to the broader goal of reducing the devastating impacts of landslide disasters on communities and environments worldwide.
Reference
Huang, F., Cao, Z., Guo, J., Jiang, S. H., Li, S., & Guo, Z. (2020). Comparisons of heuristic, general statistical and machine learning models for landslide susceptibility prediction and mapping. Catena, 191, 104580.https://doi.org/10.1016/j.catena.2020.104580
Nefeslioglu, H., Sezer, E., Gokceoglu, C., Bozkir, A., Duman, T., 2010. Assessment of landslide susceptibility by decision trees in the metropolitan area of Istanbul, Turkey. Mathematical Problems in Engineering, 2010.
Alkhasawneh, M.S., Ngah, U.K., Tay, L.T., Mat Isa, N.A., Al-Batah, M.S., 2014. Modeling and testing landslide hazard using decision tree. J. Appl. Math.
Tien Bui, D., Pradhan, B., Lofman, O., Revhaug, I., 2012. Landslide susceptibility assessment in vietnam using support vector machines, decision tree, and Naive Bayes Models. Mathematical problems in Engineering, 2012